


This is part of the blog series about building a Co-Pilot for DB Ops. The journey starts here.
Thesis
Running the co-pilot locally, on a local LLM solves a few problems:
No cost. Send as many tokens as you want
Secured: No need of any extra service, just your laptop and the production DB.
Performances and overall UX should be good enough, even on a 3 years old Mac. Remember we just generate the SQL query and the use Python code to run the query.
Implementation
I decided to use gpt4all. A free-to-use, locally running, privacy-aware chatbot. No GPU or internet required. It is free and open sourced.
The installation on MacOS is straight forward. A nice wizard guides you what to do.
Launch the tool. The UI looks a bit old, I must say. But good enough for this test.
The app itself is not big, but the LLM is 4GB - 8GB. You can select from a long list of options.
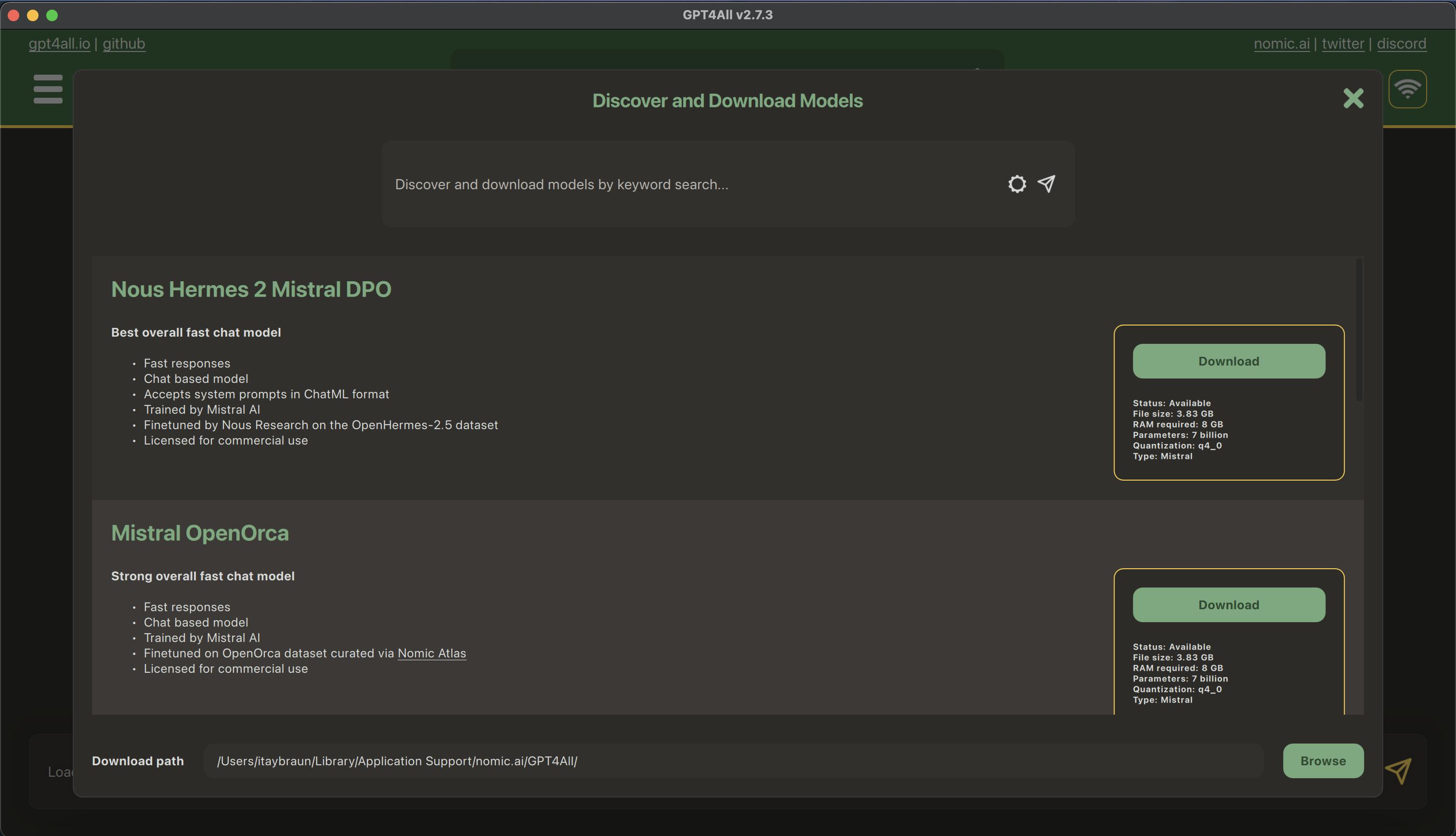
Starting with Mistral Instruct.
Local Docs
This is the main reason why I choose this product. LocalDocs is a GPT4All feature that allows you to chat with your local files and data. It allows you to utilize powerful local LLMs to chat with private data without any data leaving your computer or server. When using LocalDocs, your LLM will cite the sources that most likely contributed to a given output. Note, even an LLM equipped with LocalDocs can hallucinate. The LocalDocs plugin will utilize your documents to help answer prompts and you will see references appear below the response.
It requires an installation of SBert (43 MB)

I uploaded a file with sample SQL Queries. While the performance was kind of acceptable (4-5 seconds) the quality of the SQL was bad. Totally useless.
Thesis
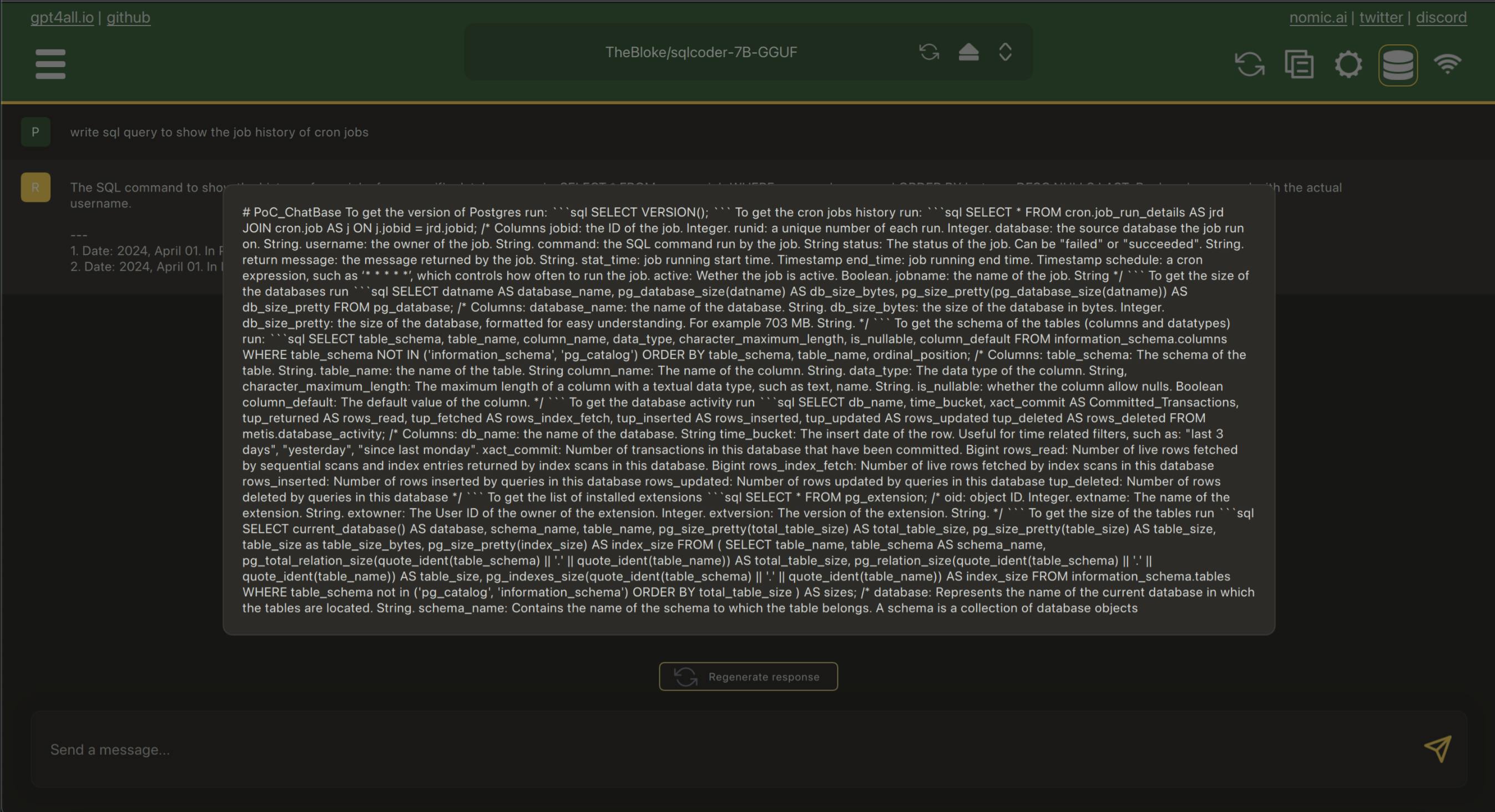
Let's try again, this time with a local LLM trained for SQL.

Results even worse than before
Conclusion
Although exploring a local LLM seems promising, I've decided not to pursue it further. Instead, I'll shift focus to testing a text2sql product, incorporating large models and RAG, such as vanna.ai. Spoiler alert: expect better results ahead.
There are similar tools, such as LMStudio, but obviously the key here is the LLM and RAG, not the UI.
Update Apr 20: Meta released Llama 3, which can run locally and supported by gpt4all. I don't plan to test it yet as venna.ai looks more promising. Once, I'll get good accuracy, I can go back to testing on a local LLM and reduce cost to 0.