


This is part of the blog series about building a Co-Pilot for DB Ops. The journey starts here.
Thesis:
The backed of the system can be Postgres. Extensions, such as pg_vectorize, can simplify adding new documents for the tests. Everything is done using plain SQL as the extension manages calling the LLM.
pg_vectorize is a Postgres extension that automates the transformation and orchestration of text to embeddings and provides hooks into the most popular LLMs. This allows you to do vector search and build LLM applications on existing data with as little as two function calls.
The Plan:
Step 1: start with learning what the system can and can't do. The sample code provided with the extension is good enough.
Step 2: Run the tests again, this time with SQL queries.
Step 1 - Implementation:
Sign up for https://tembo.io/. I'm using the free hobby edition.
Create a new instance using the RAG stack. This stack already contains all the necessary extensions.
Create the extensionCREATE EXTENSION vectorize CASCADE;
Generate the sample table "products". The table uses sample data provided by the extension. I like it.
CREATE TABLE products (LIKE vectorize.example_products INCLUDING ALL);
INSERT INTO products SELECT * FROM vectorize.example_products;
Create a job to vectorize the products table. This step prepers the data for a vector search. We'll specify the tables primary key (product_id) and the columns that we want to search (product_name and description). This adds a new column to your table, in our case it is named product_search_embeddings, then populates that data with the transformed embeddings from the product_name and description columns.
SELECT vectorize.table(
job_name => 'product_search_hf',
"table" => 'products',
primary_key => 'product_id',
columns => ARRAY['product_name', 'description'],
transformer => 'sentence-transformers/multi-qa-MiniLM-L6-dot-v1',
schedule => 'realtime'
);
The word "job" is a bit confusing, as I expected a new job in the cron.jobs table. Since the schedule is "realtime" that means there is no need for a scheduled. job.
Another important fact is using internally an open source transformer sentence-transformers/multi-qa-MiniLM-L6-dot-v1. This is a sentence-transformersmodel: It maps sentences & paragraphs to a 384 dimensional dense vector space and was designed for semantic search. It has been trained on 215M (question, answer) pairs from diverse sources. From the documentation I couldn't see any other options. Notice that at this point no LLM is used and everything is Free.
Search the data using a semantic search via an SQL function!
SELECT * FROM vectorize.search(
job_name => 'product_search_hf',
query => 'accessories for mobile devices',
return_columns => ARRAY['product_id', 'product_name'],
num_results => 3
);
Results:
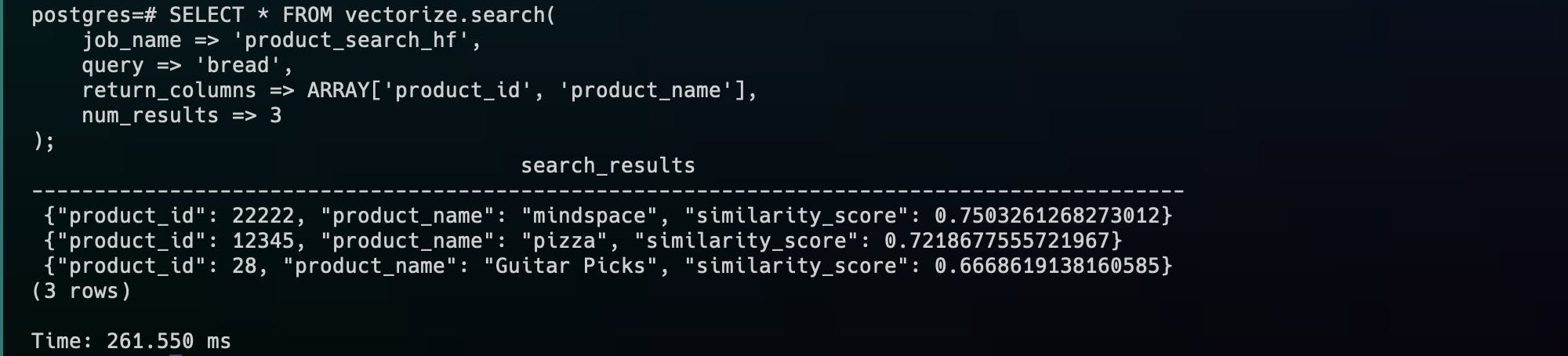
As you can see, the query duration is 260ms, searching in a table with under 30 rows. More tests are needed on larger volumes. I know vector indexes exist but haven't learned how to use them. Too soon.
Using RAG
Now, since an LLM is used, the extension must be configured with a valid API Key. As far as I understand, only OpenAI is supported now.
ALTER SYSTEM SET vectorize.openai_key TO '<your api key>';
SELECT pg_reload_conf();
In the example, the next step is creating a new virtual column that we want to use as the context. In this case, we'll concatenate both product_name and description.
ALTER TABLE products
ADD COLUMN context TEXT GENERATED ALWAYS AS (product_name || ': ' || description) STORED;
The results:

Initialization the RAG. That generates a job to create the necessary vector data. In my tests I had to wait a big before new data was ready for the RAG.
SELECT vectorize.init_rag(
agent_name => 'product_chat',
table_name => 'products',
"column" => 'context',
unique_record_id => 'product_id',
transformer => 'sentence-transformers/all-MiniLM-L12-v2'
);
Search for the data:
SELECT vectorize.rag(
agent_name => 'product_chat',
query => 'What is a pencil?'
) -> 'chat_response';
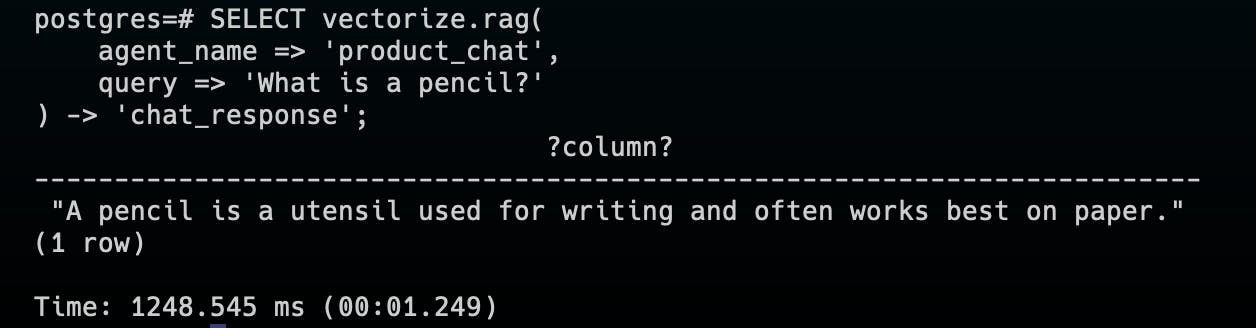
Notice the time, 1-2 seconds.
To further test the system I added a new product called "mindspace" with the description "A special yellow and green bread".

Notice that this time I want to see the JSON of the results to get a better understanding of it.
Conclusion
The flow is simple. Easy to manage the training data.
Performance - Not great. 1200ms just to get the SQL, before running it and the UI overhead. But I still want to further test this direction.
Cost of the OpenAI API - I need to run more tests. I would expect an easy way to see the number of tokens used.
Next step:
Try it with real-world data. However, while working on other technologies I'm under the impression than an LLM trained for SQL should be used. So probably it would be smarter to start there. As I wrote above, I think here I'm limited with the LLM I can use.