


This is part of the blog series about building a Co-Pilot for DB Ops. The journey starts here.
Thesis
Fetching data from the system tables (performance schema) is basically a text2sql task. A good text2sql solution should be able to generate high quality SQL. Such a tool should support, out-of-the-box, training the AI model with detailed instruction about the schema and some examples of queries. Without it, I don't expect the solution to provide accurate SQL.
I do expect the SQL to be valid as this is the main goal of text2sql...
About Vanna.ai
There are many text2sql tools. I played with some (too busy to cover them in this series). I decided to test vanna.ai.
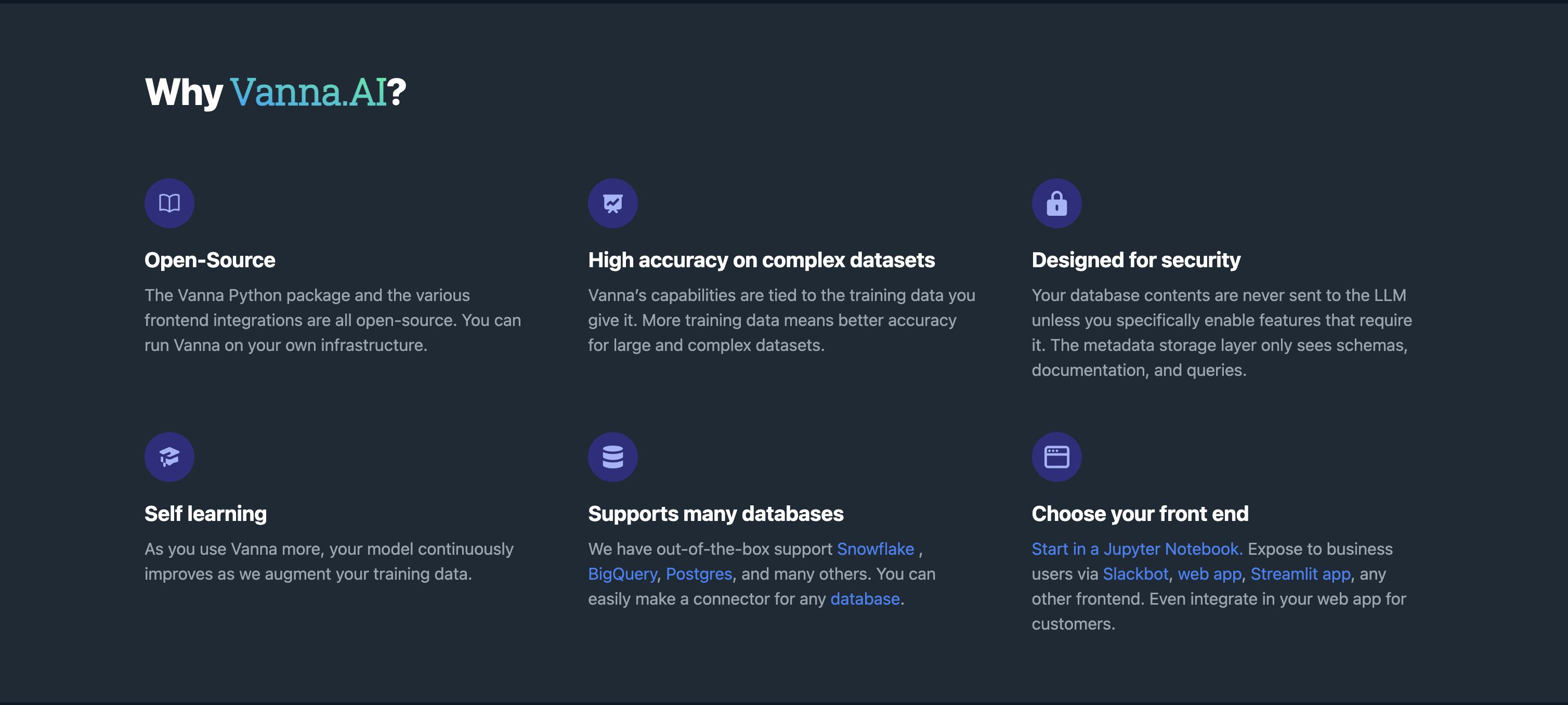
Open source with 6K stars.
Generous free tier
Allow custom training on your data using a simple UX.
I also must say they have a good documentation with a Colab notebook so you can run it with a demo data easily. I really like this approach.
Running the Colab Notebook
# Run once
!pip install vanna
I have a PostgreSQL on Tembo cloud. It is free and you can easily install more than 200 extensions. I wrote here about PostgreSQL as a Service.
I also signed up to venna and got an API Key. That API Key provides free tokens, enough for the test.
from google.colab import userdata
## Get the API Key from the Colab secrets
vanna_apikey = userdata.get('vanna_apikey')
from vanna.remote import VannaDefault
vn = VannaDefault(model='metis_1', api_key=vanna_apikey)
## Connect to Postgres
vn.connect_to_postgres(host='org-metis-inst-12345.use1.tembo.io', dbname='postgres', user='postgres', password='YOUR_PASSWORD', port='5432')
Load the columns. This step might take a while, maybe even 2 minutes.
# The information schema query may need some tweaking depending on your database. This is a good starting point.
# I only want to train on the system tables: SELECT table_schema, table_name, column_name, data_type FROM information_schema.columns WHERE table_schema = 'pg_catalog';
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
# This will break up the information schema into bite-sized chunks that can be referenced by the LLM
plan = vn.get_training_plan_generic(df_information_schema)
plan
# If you like the plan, then uncomment this and run it to train
vn.train(plan=plan)
Custom Data
This is why I chose vanna. You can train the model using your database schema:
DDL - Not needed at this point
Documentation - At this early version, the SQL commands contains comments with all the necessary information.
SQL commands - Query + detailed comments.
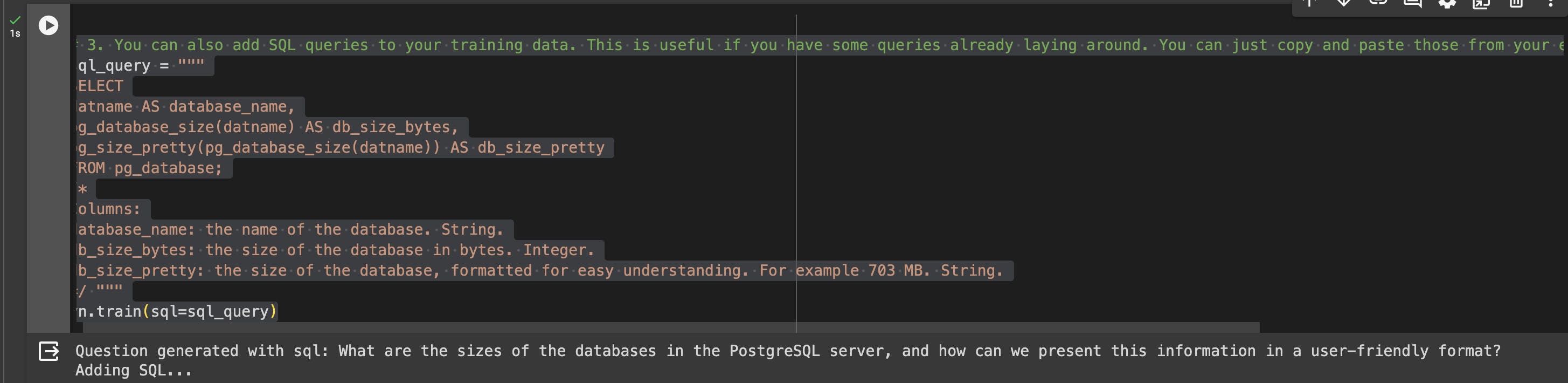
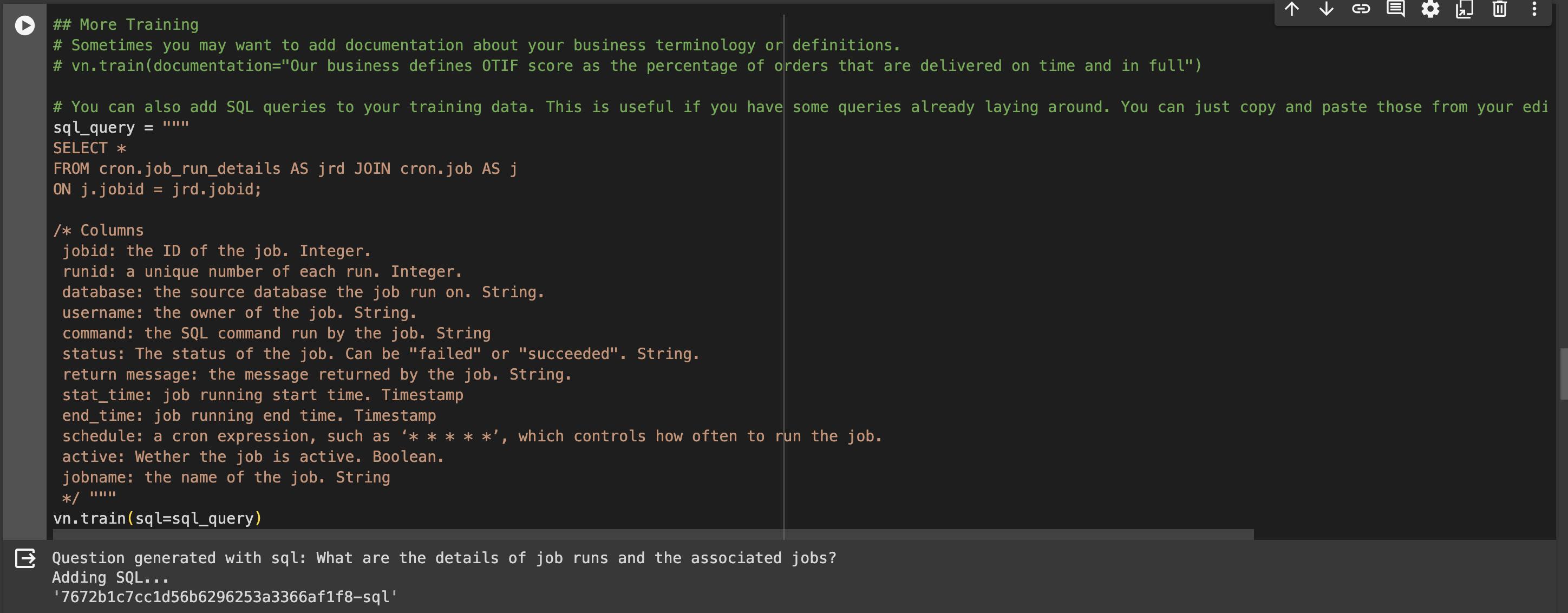
# 3. You can also add SQL queries to your training data. This is useful if you have some queries already laying around. You can just copy and paste those from your editor to begin generating new SQL.
sql_query = """
SELECT
datname AS database_name,
pg_database_size(datname) AS db_size_bytes,
pg_size_pretty(pg_database_size(datname)) AS db_size_pretty
FROM pg_database;
/*
Columns:
database_name: the name of the database. String.
db_size_bytes: the size of the database in bytes. Integer.
db_size_pretty: the size of the database, formatted for easy understanding. For example 703 MB. String.
*/ """
vn.train(sql=sql_query)
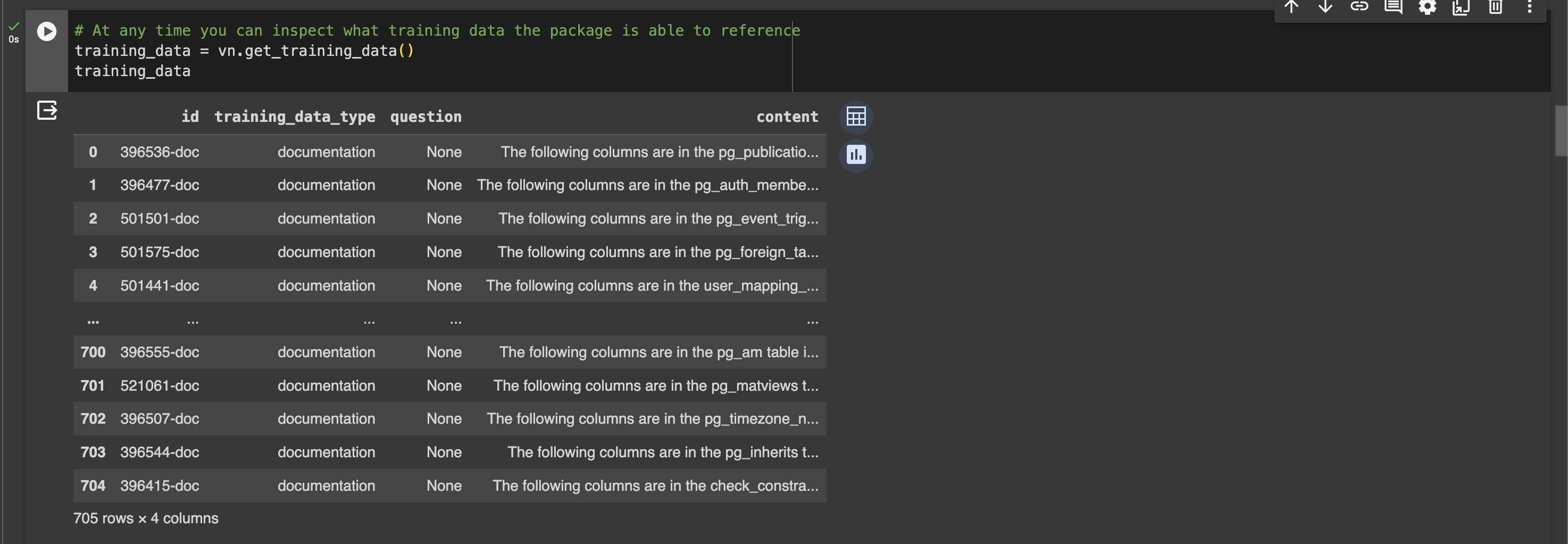
View the training data
Now we can start asking questions using the model. Vanna will
Generate a query
Run it
Return the results as a data set
visualize it. I found the visualization as not useful to my tests to I called the
askmethod without it
vn.ask(question="write the SQL query to answer the question: what is the size of the databases?", visualize = False);
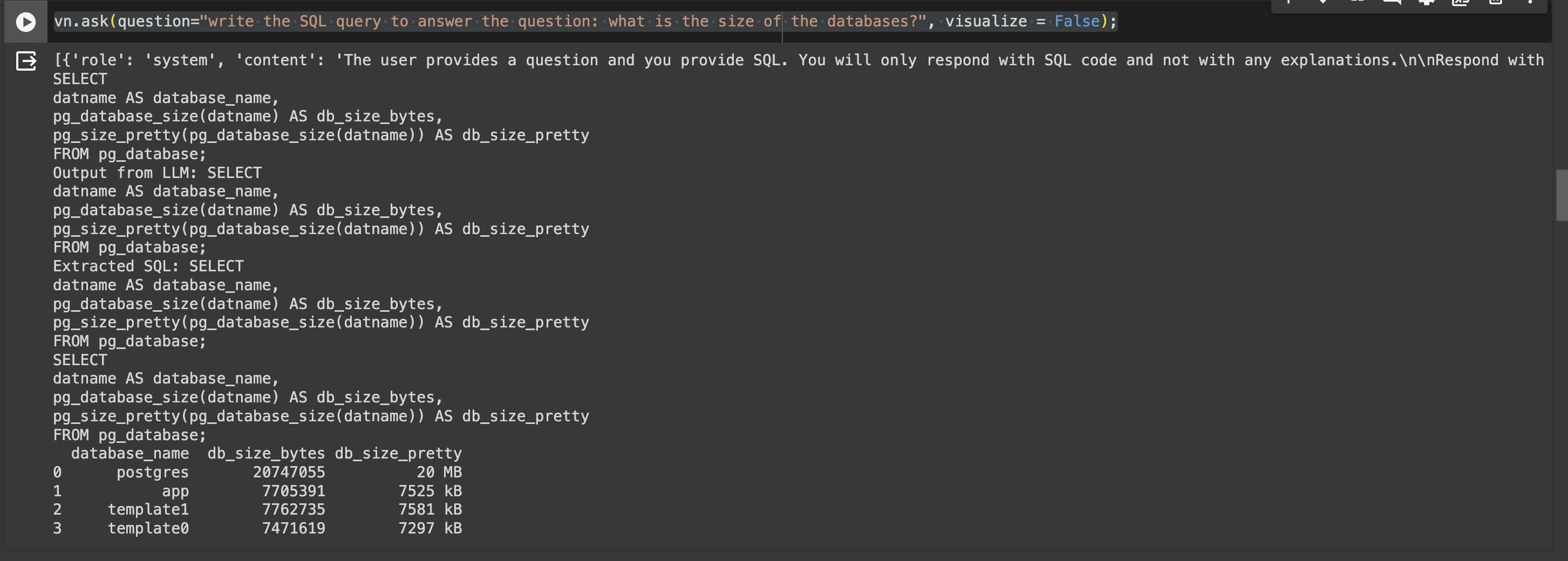
Another test

More tests
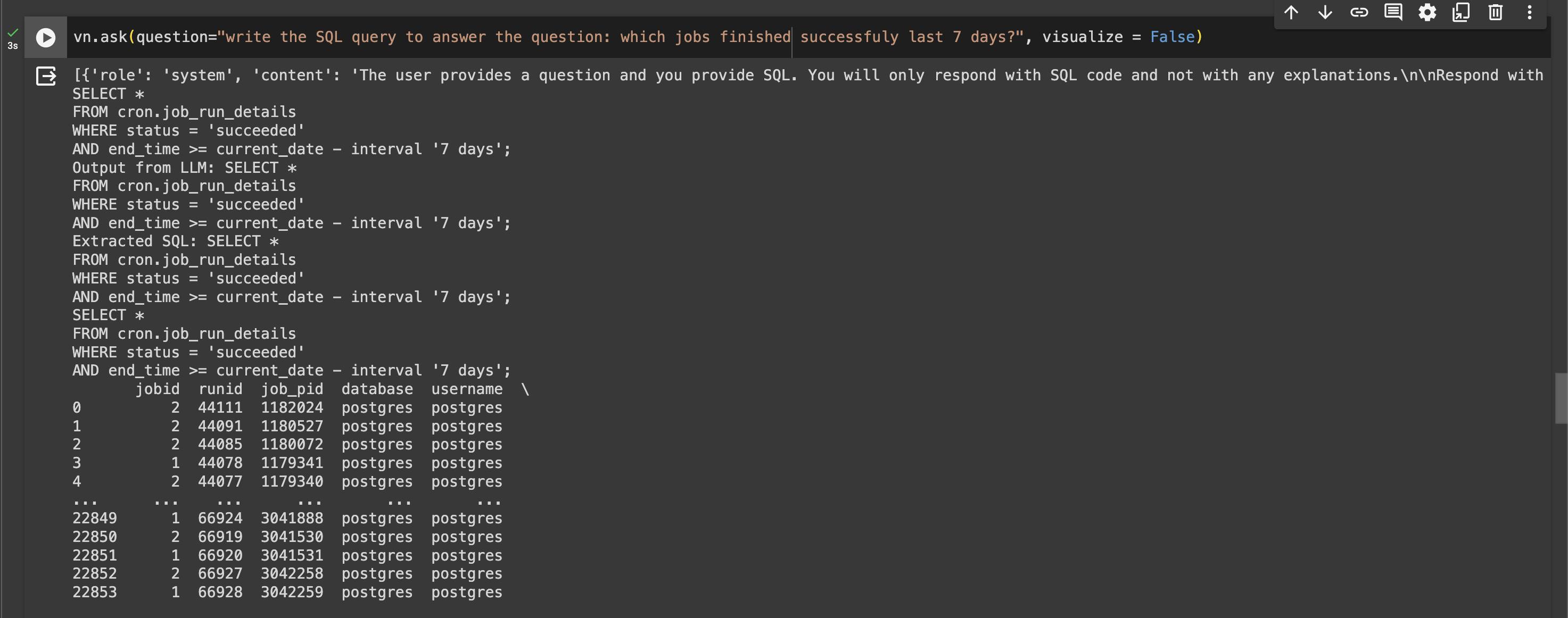
So far so good.
The SQL is valid.
The query is what I expect, using the custom data.
Training of the new query was 1 second.
Good performance: 23K rows under 3 seconds
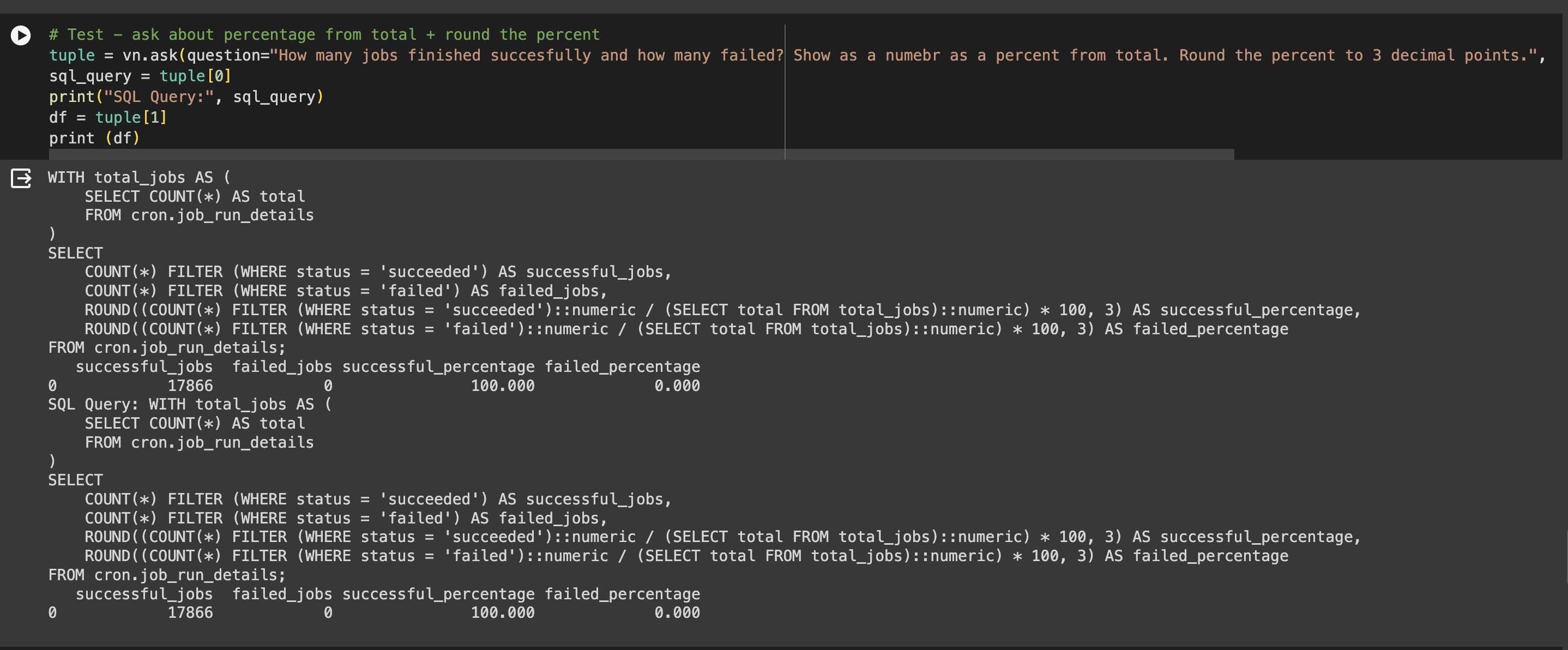
ask call.More tests
Conclusion
Vanna.ai looks promising. I need to train the system with more use cases and check the quality of the results. Maybe it would break with 100+ different subject to test (WAL Activity, indexes usage, table size, permissions to users....).