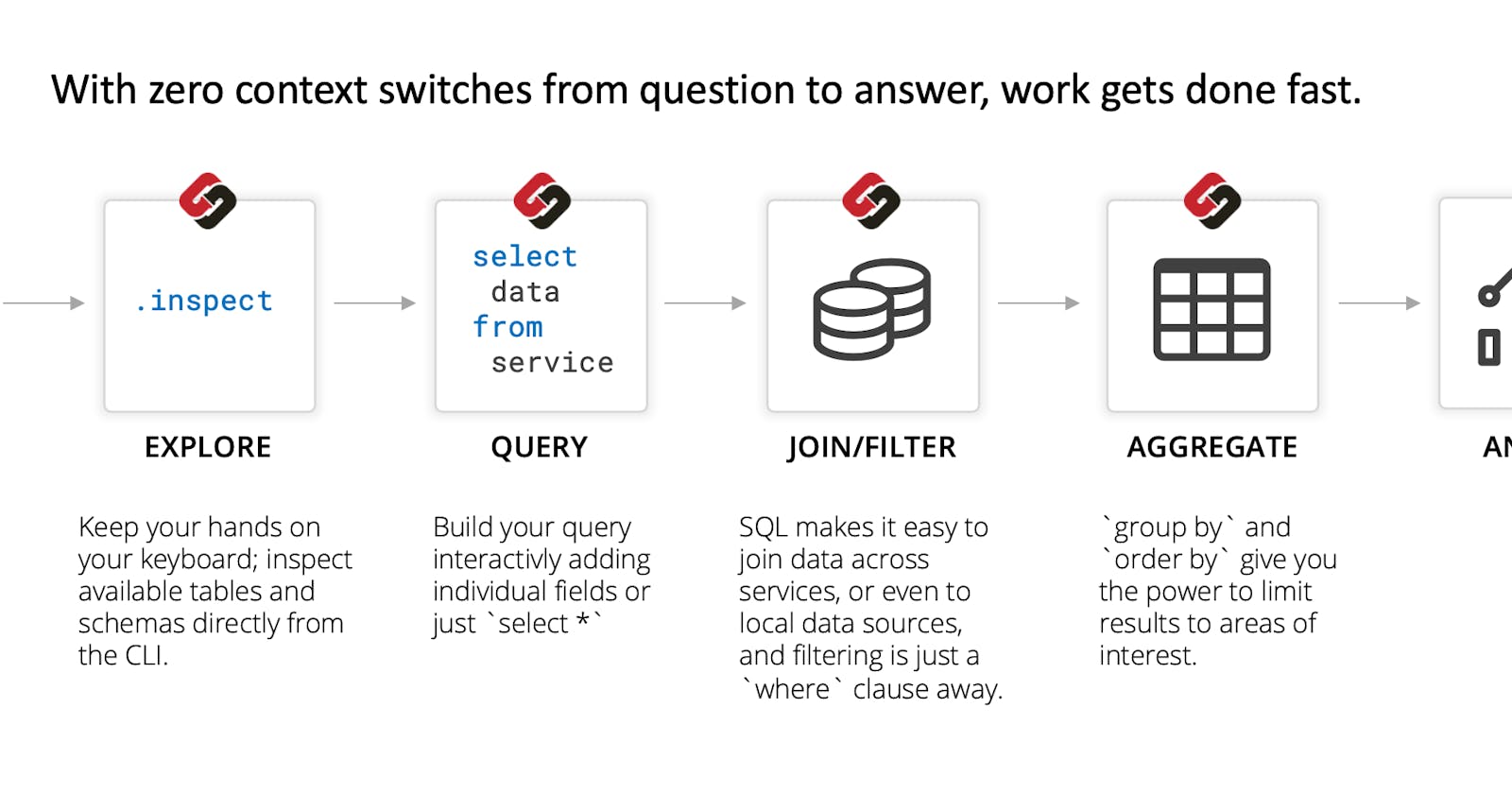
Query the AWS RDS Configuration and Performance Metrics using SteamPipe
You don't need to use the AWS SDK, just good old SQL!


In this post, you'll learn about a useful and simple CLI tool called SteamPipe to easily query the configuration properties of the RDS and its performance Metrics.
Why should I care?
While working with the RDS, you probably want some automation via scripts to get useful information. You can always use the native AWS CLI. However, querying the metadata using SQL opens many options. With SQL you can build dashboards, define rules or join the data with other data sources (using SteamPipe or any other SQL).
Can you give me 3 real-world examples?
SteamPipe, via their hub of plugins, offers many connectors for the main cloud vendors. For AWS alone there are more than 300 tables, most of which are not for RDS. In this post, I'll focus only on AWS RDS, hence the examples are only for this subject. But you can do much more than querying only the AWS RDS configuration.
- View the instance details, such as instance type (how many CPU and memory), whether is it publicly available, view the Slow Query Log configuration and whether performance insights are configured.
- View the performance metrics of the RDS from CloudWatch, such as CPU and free disk space
- Analyze the impact of releasing a new version on the CPU and memory by joining data from CloudWatch and GitHub.
What is SteamPipe
SteamPipe let you explore, connect and join data. Painlessly join live cloud configuration data with internal or external data sets to create new insights. The hub of plugins offers plugins for AWS, GCS, Azure, Alibaba cloud and many more. You can query the data using their CLI or web app. Since SteamPipe is actually a Postgres DB, you can also query the cloud as if you query any other Postgres Table. They explain better than me about their vision.
Installation and Configuration
The installation is pretty straightforward: steampipe.io/downloads . Install the AWS plugin hub.steampipe.io/plugins/turbot/aws
steampipe plugin install steampipe
A new configuration file is created at the path ~/.steampipe/config/aws.spc . Here you'll configure the credentials and regions of your AWS account. The file is similar to this and should contain your Access Key and Access Key ID.
It is strongly recommended to create a dedicated AWS User, with the least privileges for read-only the RDS and CloudWatch metadata.
Query the AWS RDS configuration
You can start querying the cloud from the CLI or using your favorite Postgres IDE. Let's start with the CLI. To enter "Query Mode" run the command:
steampipe query
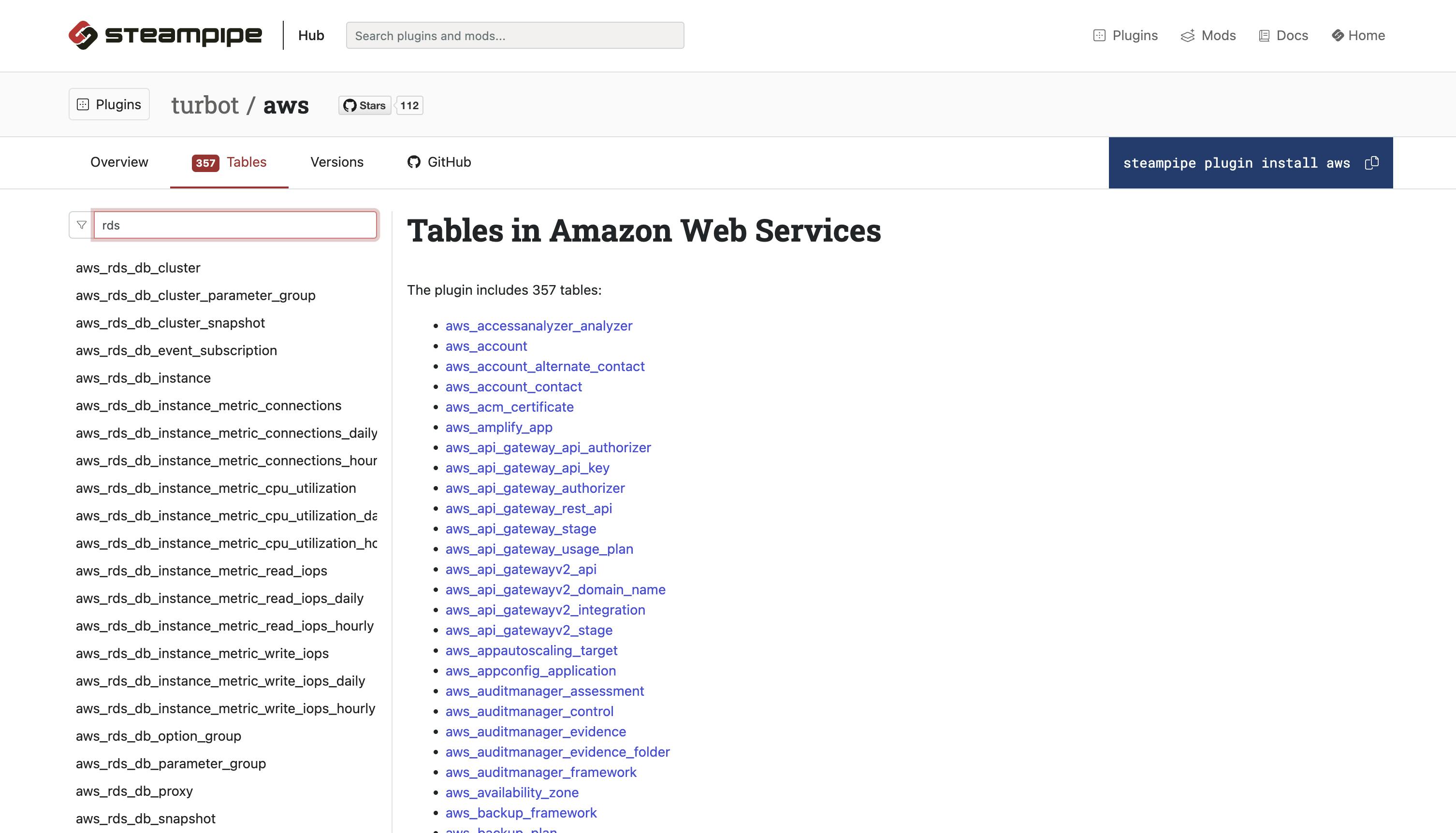
AWS has many tables you can query. The documentation,hub.steampipe.io/plugins/turbot/aws/tables?.. , describes them all. In the image below I searched only the RDS tables:
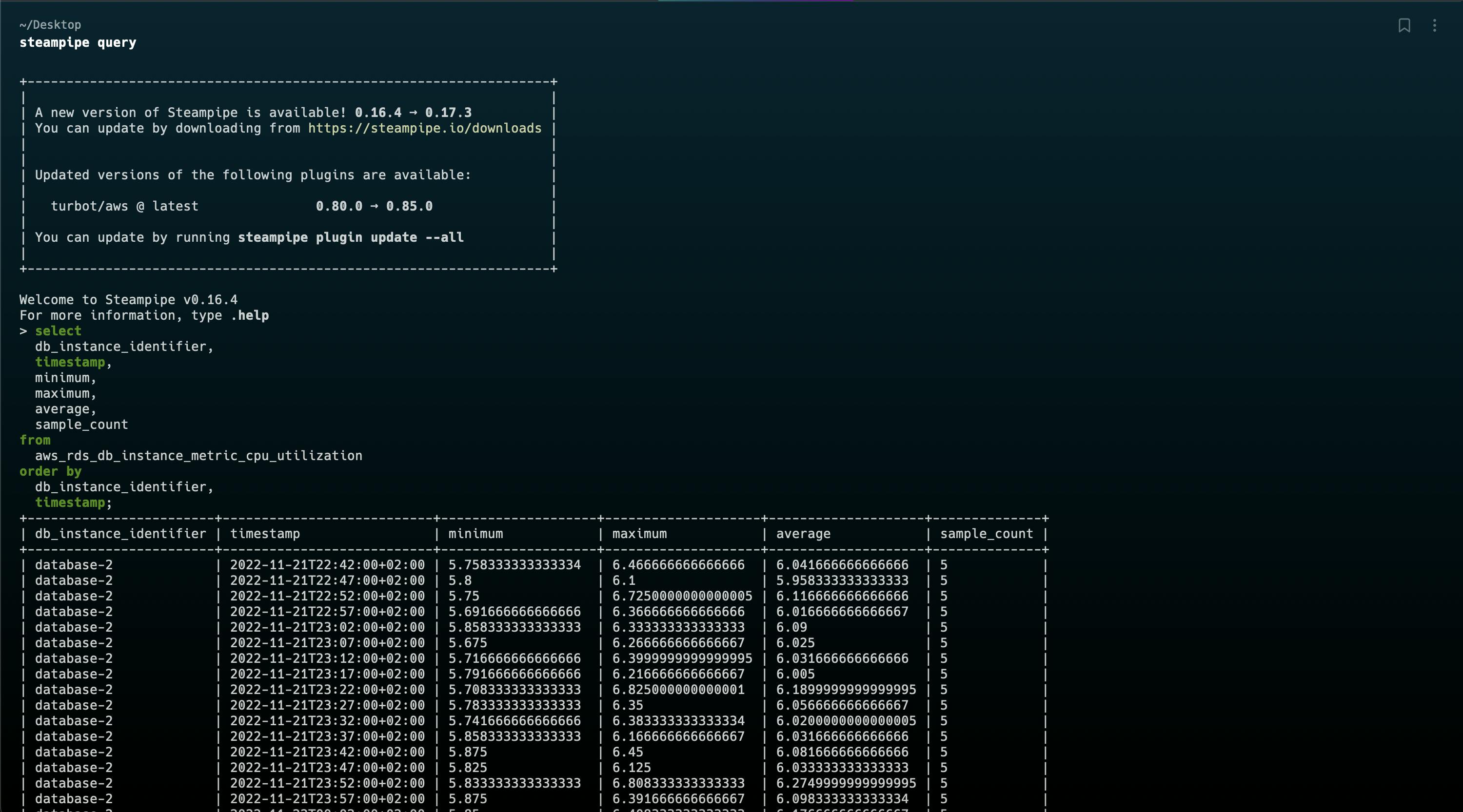
Run a query. For ex. the table aws_rds_db_instance_metric_cpu_utilization provides metric statistics at 5 minute intervals for the most recent 5 days from AWS CloudWatch.
select
db_instance_identifier,
timestamp,
minimum,
maximum,
average,
sample_count
from
aws_rds_db_instance_metric_cpu_utilization
order by
db_instance_identifier,
timestamp;
Tip - The AWS API might have some limitations regarding the number of returned cells. Therefore it is recommended to use only the really needed columns and filter the data to return only the relevant rows. Else a query that worked might stop working suddenly because it now returns too much data.
Using the Internal Postgres DB
Under the hood, SteamPipe uses foreign data wrappers to connect to AWS. To connect to the local Postgres server, you'll need a connection string: name, port, user name and password. Run the command
steampipe service start --show-password
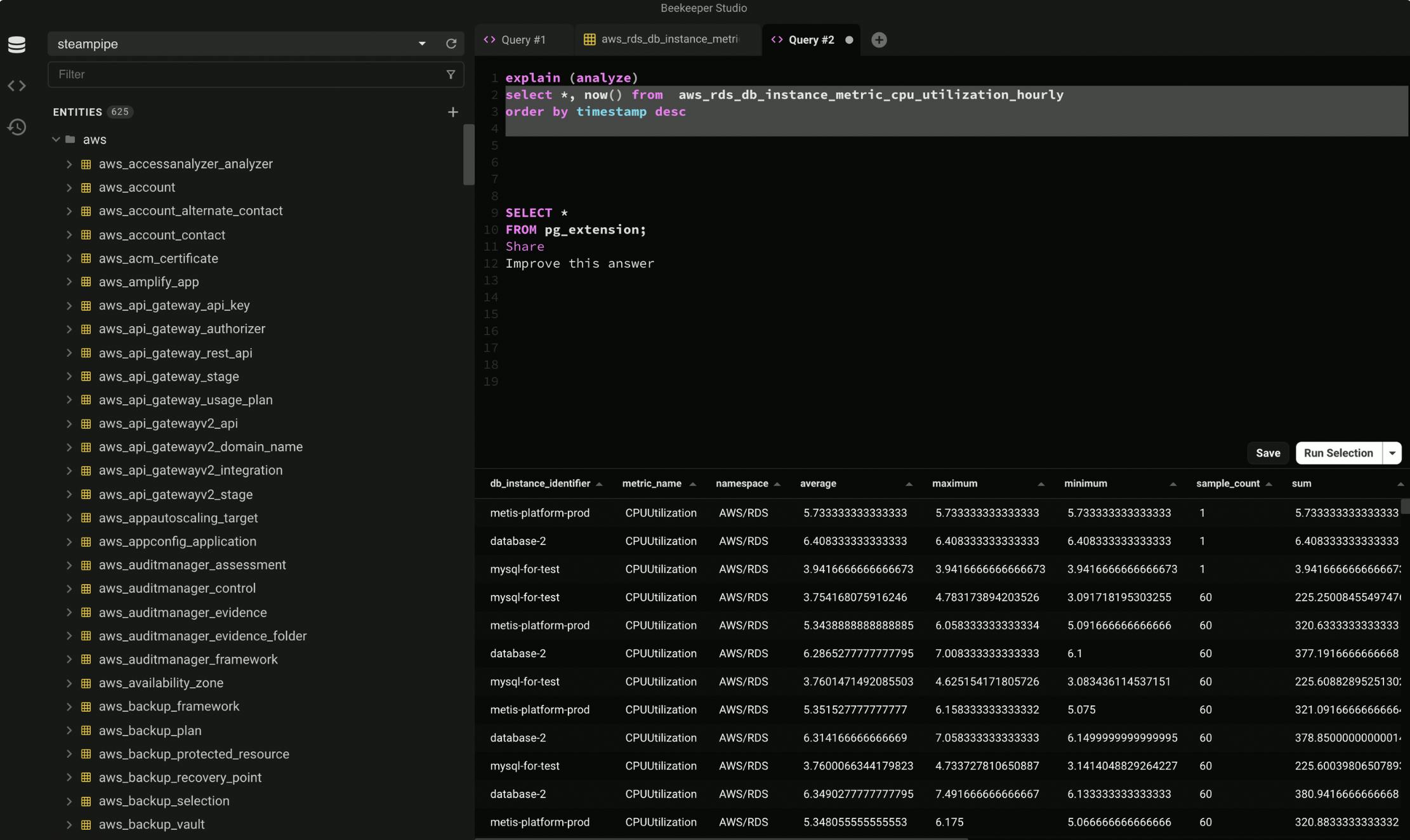
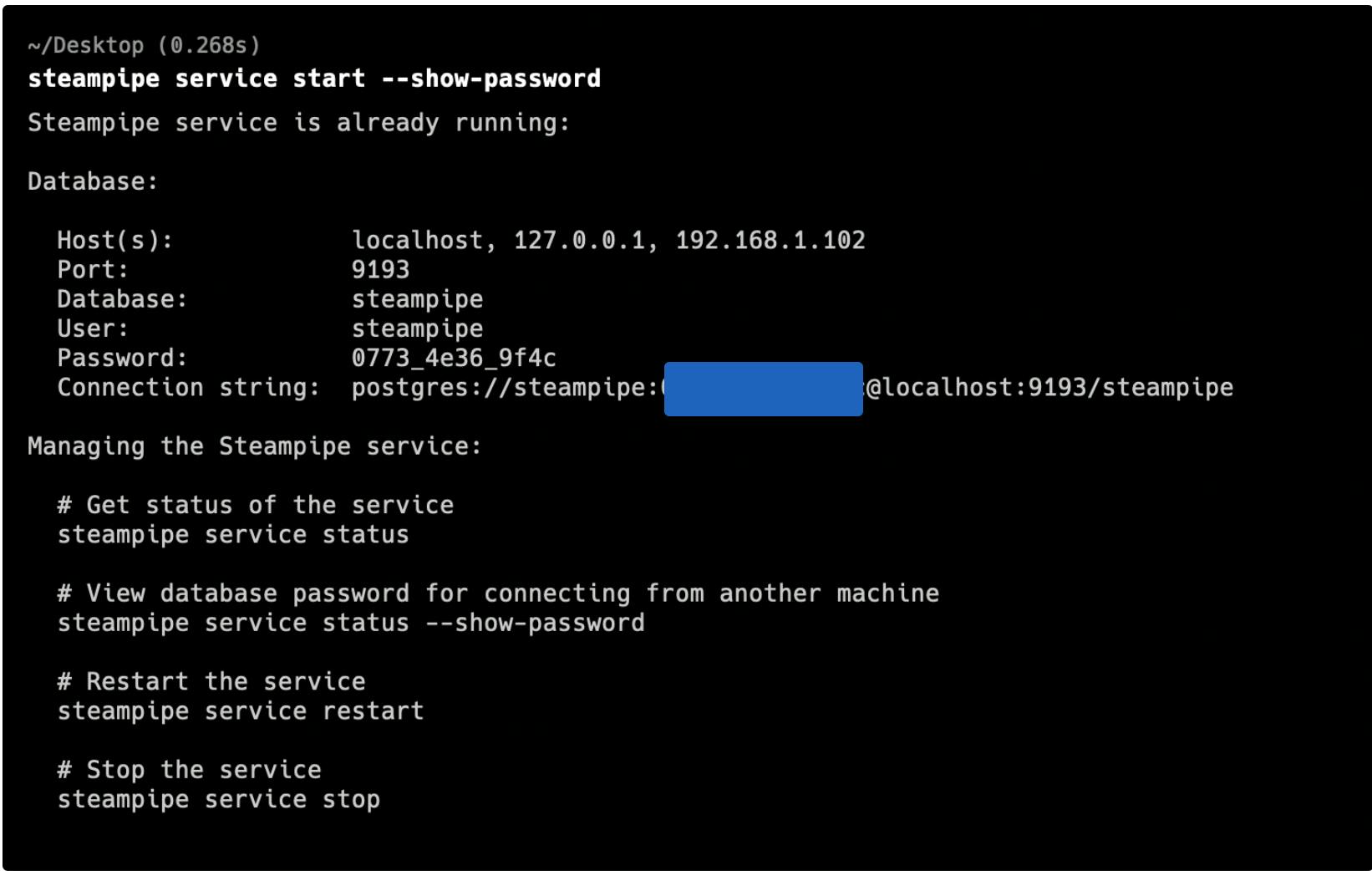 Now you have all the information to connect to the Postgres DB using any SQL IDE. In the example below I'm using BeeKeeper
Now you have all the information to connect to the Postgres DB using any SQL IDE. In the example below I'm using BeeKeeper
Conclusion
SteamPipe is a simple yet very useful tool to query the cloud as SQL. It is one of the tools in my toolbox to get quick answers. But in many cases, I'm limited to the existing tables, while I need information they do not provide. Writing SQL is great but using the Python AWS SDK (boto3), aws.amazon.com/sdk-for-python with Python Pandas DataFrame is much more powerful. Instead of SQL, pandas provide an easy-to-learn method to filter and group the data. I'll write soon about how to implement similar functionality with AWS SDK + Pandas. And DuckDB integration if you prefer using SQL.