

A Repost is Sharing a high-quality content, written by people I appreciate.
Figma published a blog post about their unique implementation of sharding. The article is about Figma's journey to horizontally shard their Postgres database. The blog post also opened a discussion in Hacker News.
TLDR
Figma's database grew so big that vertical partitioning wasn't enough anymore. They decided to horizontally shard the database, which means splitting the data across multiple servers.
This is a complex process that can introduce reliability issues. Figma developed a custom solution to shard their database while minimizing risks
Figma's solution for horizontally sharding their Postgres database involved several key components:
Colocation (Colos): Instead of sharding each table independently, Figma grouped related tables into colos (a term they invented). This allowed them to share the same sharding key and physical sharding layout, simplifying development for these commonly accessed groups and minimize joins over the network with other shards.
Logical vs. Physical Sharding: To de-risk the rollout, Figma separated logical sharding (application layer) from physical sharding (database layer). This enabled them to test the application's readiness for sharding with minimal data movement and rollback capabilities.
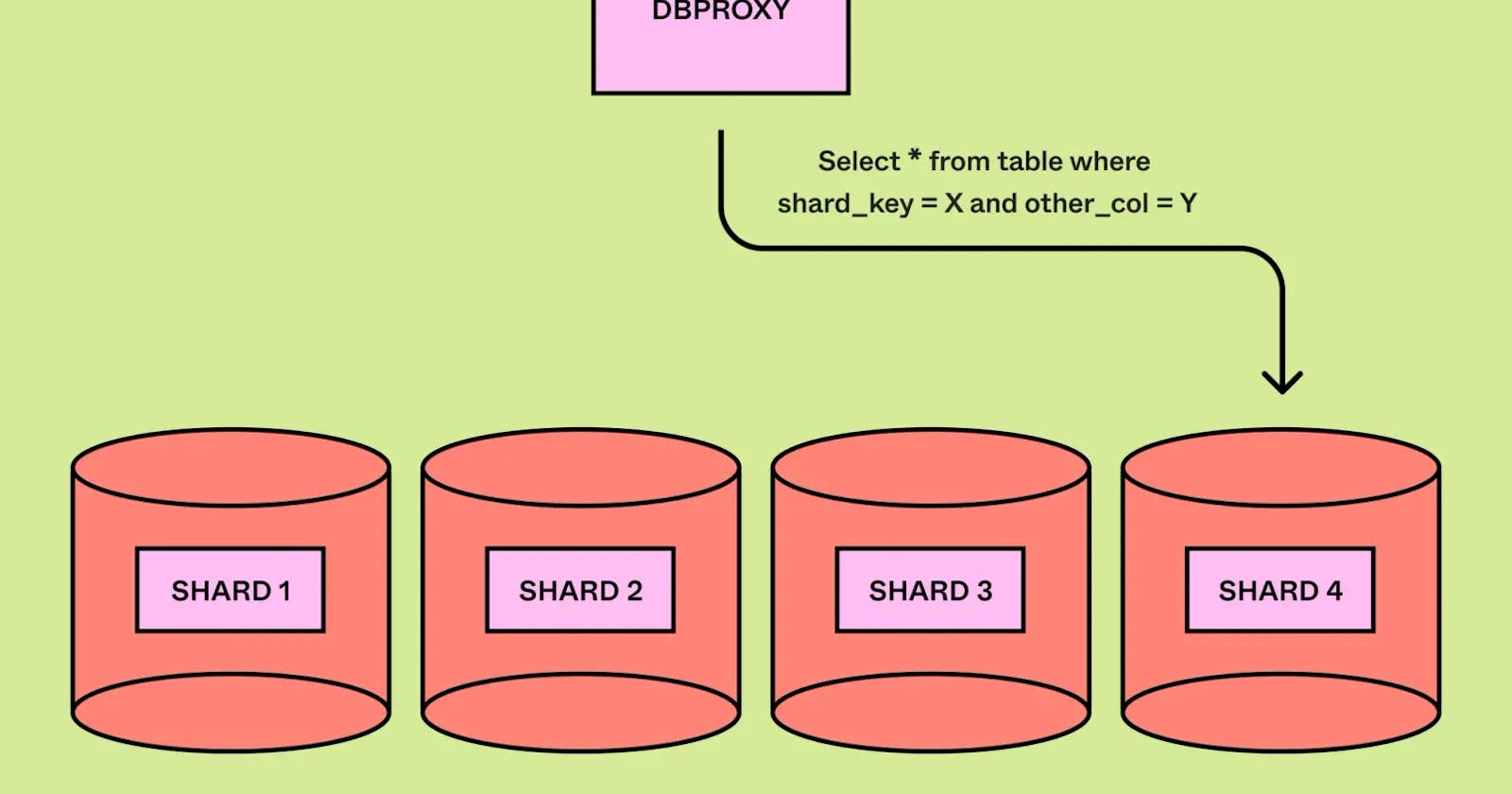
DBProxy Service: This custom service sits between the application and the database, handling query routing, load balancing, and limited query execution. It includes a lightweight query engine that can parse and rewrite complex queries for sharded databases. DBProxy relies on understanding the database layout, so Figma built a system to manage the topology of tables, physical databases, and shard mappings. This system updates dynamically during shard splits and ensures data is routed to the correct databases.
Sharding Key Selection: Since sharding relies on a specific key to distribute data, Figma carefully chose keys like UserID, FileID, or OrgID that minimized the need for complex data migrations and ensured even data distribution.
Hashing for Shard Key: Auto-incrementing IDs wouldn't distribute data evenly across shards. Figma addressed this by hashing the sharding key, ensuring even distribution but potentially impacting range scans on those keys (considered a less frequent query pattern).
My Take
This is a great example of how PostgreSQL can be leveraged to support huge volumes of data and a massive number of concurrent transactions.
Sharding Postgres? Look at the execution plan. Figma's experience sharding their database shows us a key step to success: checking how your queries access data. This means understanding:
Tables involved: Are tables you join together scattered across different shards? This can slow things down. Ideally, frequently joined tables should be sharded together.
Data location: Where's the data stored (which shard)? Joins are faster if the data is already on the same shard, reducing network traffic.
Network traffic: Queries that join data from different shards require data to travel over the network, which can be slow. Sharding strategically helps minimize this.
Figma's PostgreSQL sharding is impressive, but complex. Building a custom query engine like their DBProxy is a resource-intensive endeavor, justified only in extreme cases.
Explore distributed Postgres solutions like YugabyteDB first. These proven platforms handle massive data volumes without custom engines, often offering automatic sharding, high availability, and transparent data distribution. Evaluate them first before embarking on custom sharding.
Figma's emphasis on incremental rollouts is a crucial takeaway for anyone considering database changes. Unlike software, database modifications are notoriously difficult to rollback. A single misstep can lead to significant downtime or data loss. Figma's measured approach, prioritizing small, testable steps, exemplifies how to mitigate risk and ensure application stability during complex database operations. In their words: Make incremental progress: We identified approaches that could be rolled out incrementally as we de-risked major production changes. This reduced the risk of major outages and allowed the databases team to maintain Figma’s reliability throughout the migration.